首页
视频
资源
登录
原
HugginFace 使用训练工具(学习笔记)
3678
人阅读
2023/10/25 14:57
总访问:
2860563
评论:
0
收藏:
0
手机
分类:
HuggingFace
 >#HugginFace 使用训练工具(学习笔记) [TOC] ## 训练工具介绍 tn2>HuggingFace提供了巨大的模型库,但我们往往还需要对特定的数据集进行二次训练,这个过程也叫做迁移学习。 这里我们以情感分类的任务作为例子。 ## 使用训练工具 tn2>再此之前,我安装的框架环境版本如下: ```python %pip install -q transformers==4.18 datasets==2.4.0 torchtext ``` ### 准备数据集 #### 加载编码工具 tn2>首先加载一个编码工具,由于编码工具和模型往往是成对使用的,所以这里使用`hfl/rbt3`编码工具,因为要再训练的模型是`hfl/rbt3`模型,代码如下: ```python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('hfl/rbt3') tokenizer ```  tn2>加载了编码工具后,简单的测试一下: ```python tokenizer.batch_encode_plus( ['明月装饰了你的窗子', '你装饰了别人的梦'], truncation=True, ) ```  #### 准备数据集 tn2>加载数据集,使用该数据集再来训练模型,代码如下: ```python from datasets import load_dataset dataset = load_dataset("lansinuote/ChnSentiCorp") #缩小数据规模,便于测试 shuffle 打乱顺序 dataset['train'] = dataset['train'].shuffle().select(range(2000)) dataset['test'] = dataset['test'].shuffle().select(range(100)) dataset ``` tn2>这段代码对数据进行了采样,一是便于测试,二是模拟再训练集的体量较小的情况,以验证即使是小的数据集,也能通过迁移学习得到一个较好的训练结果。运行结果如下: 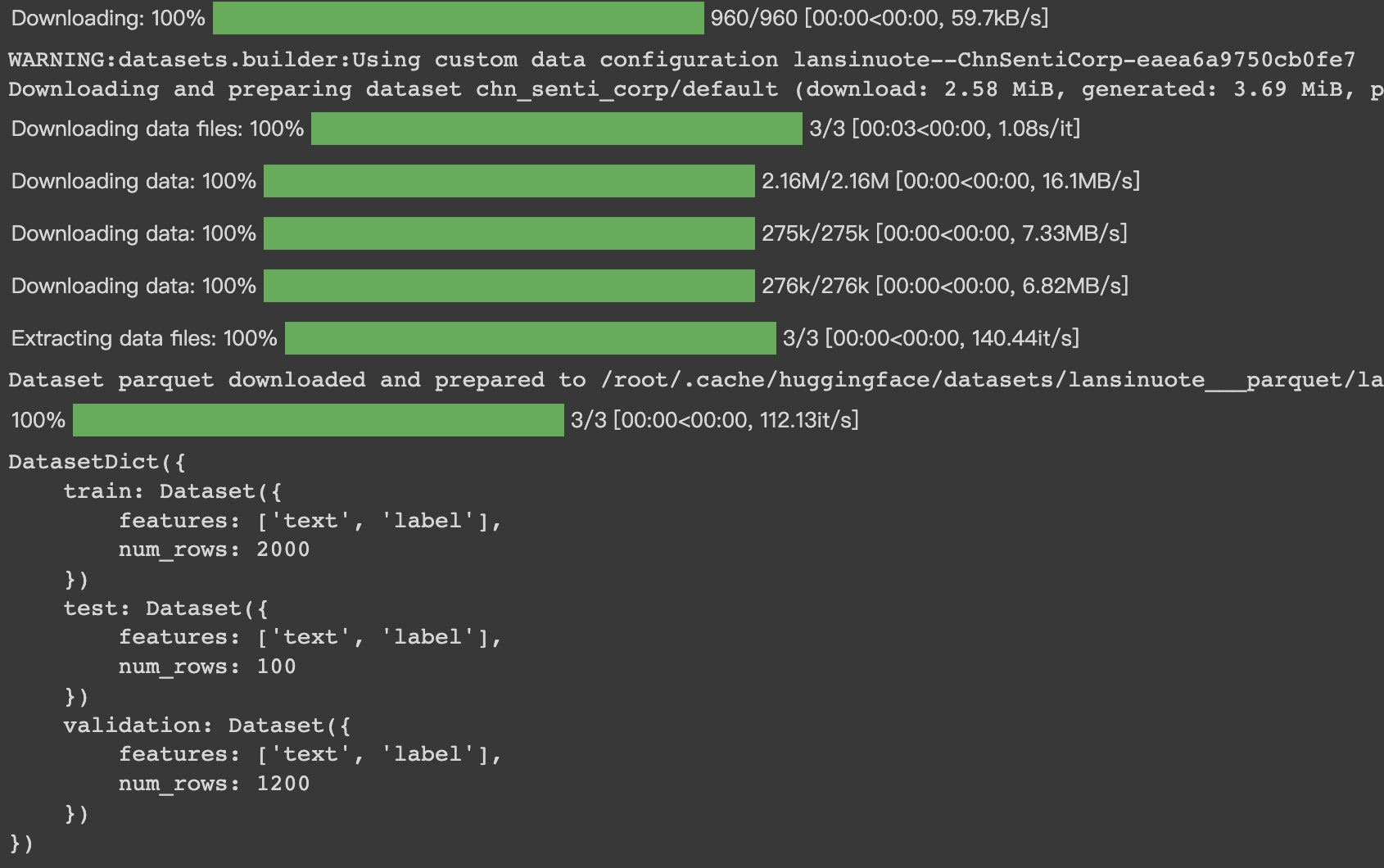 tn2>可见训练集的数量仅有2000条,测试集的数量有100条。 现在的数据集还是文本数据,使用编码工具把这些抽象的文字编码成计算机善于处理的数字,代码如下: ```python #第6章/编码 def f(data): return tokenizer.batch_encode_plus(data['text'], truncation=True) dataset = dataset.map(f, batched=True, batch_size=1000, num_proc=4, remove_columns=['text']) dataset ``` | 参数 | 描述 | | ------------ | ------------ | |`batch` | 为True表明使用批处理来处理数据,而不是一条一条地处理。 | | `batch_size` | 为1000表明每个批次有1000条数据 | | `num_proc` | 为4表明使用4个线程进行操作。 | | `remove_columns` | 这里表示映射结束后删除text字段 | 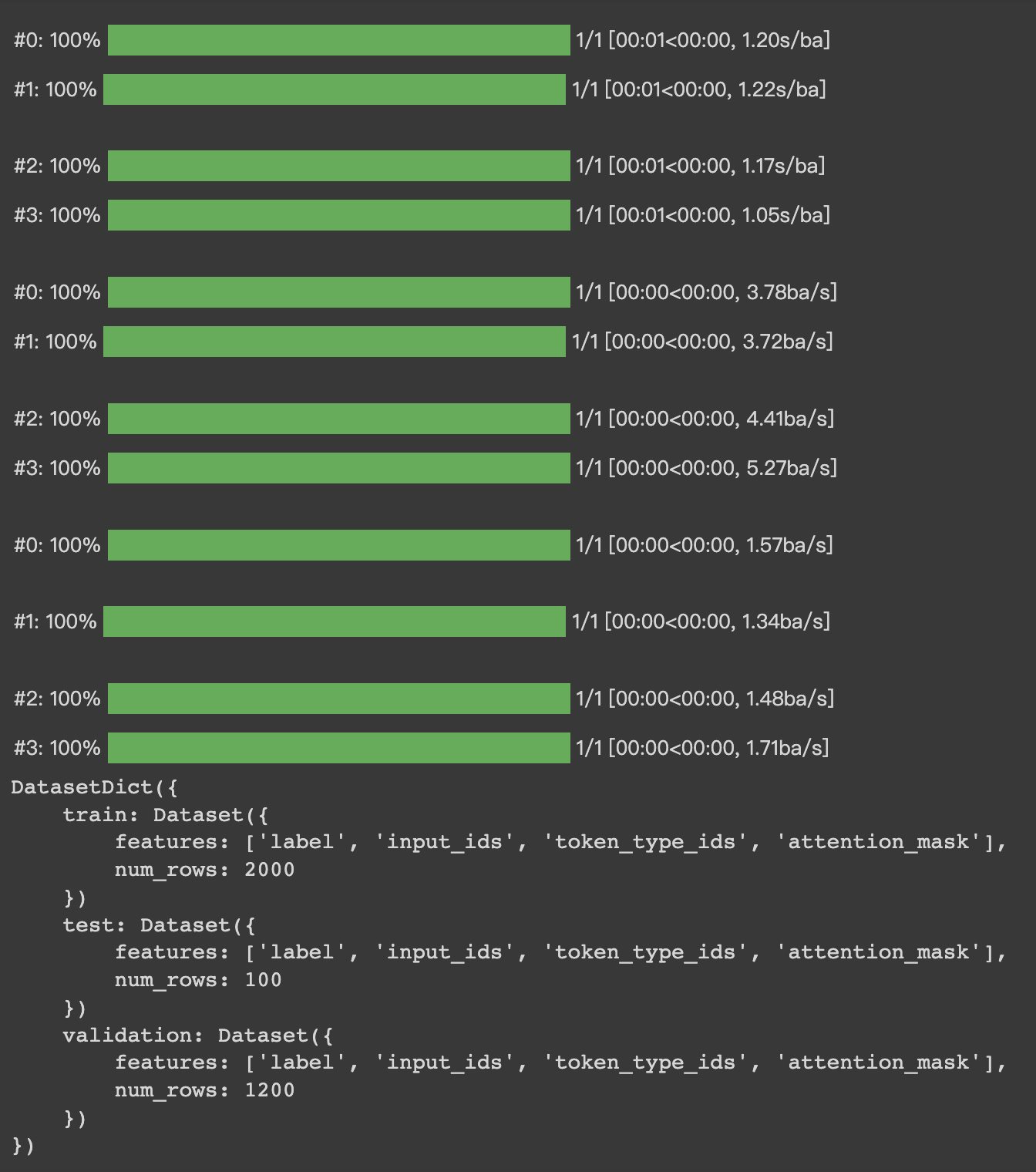 tn2>我们可以看到原来的`text`已经被删除了,但多了`input_ids`(编码)、`token_type_ids`、`attention_mask`字段,这些字段是编码工具编码的结果,折合前面观察到的编码器试算的结果一致。 接下来,我们将句子抄过超过512长度的句子过滤掉。 ```python def f(data): return [len(i) <= 512 for i in data['input_ids']] dataset = dataset.filter(f, batched=True, batch_size=1000, num_proc=4) dataset ``` 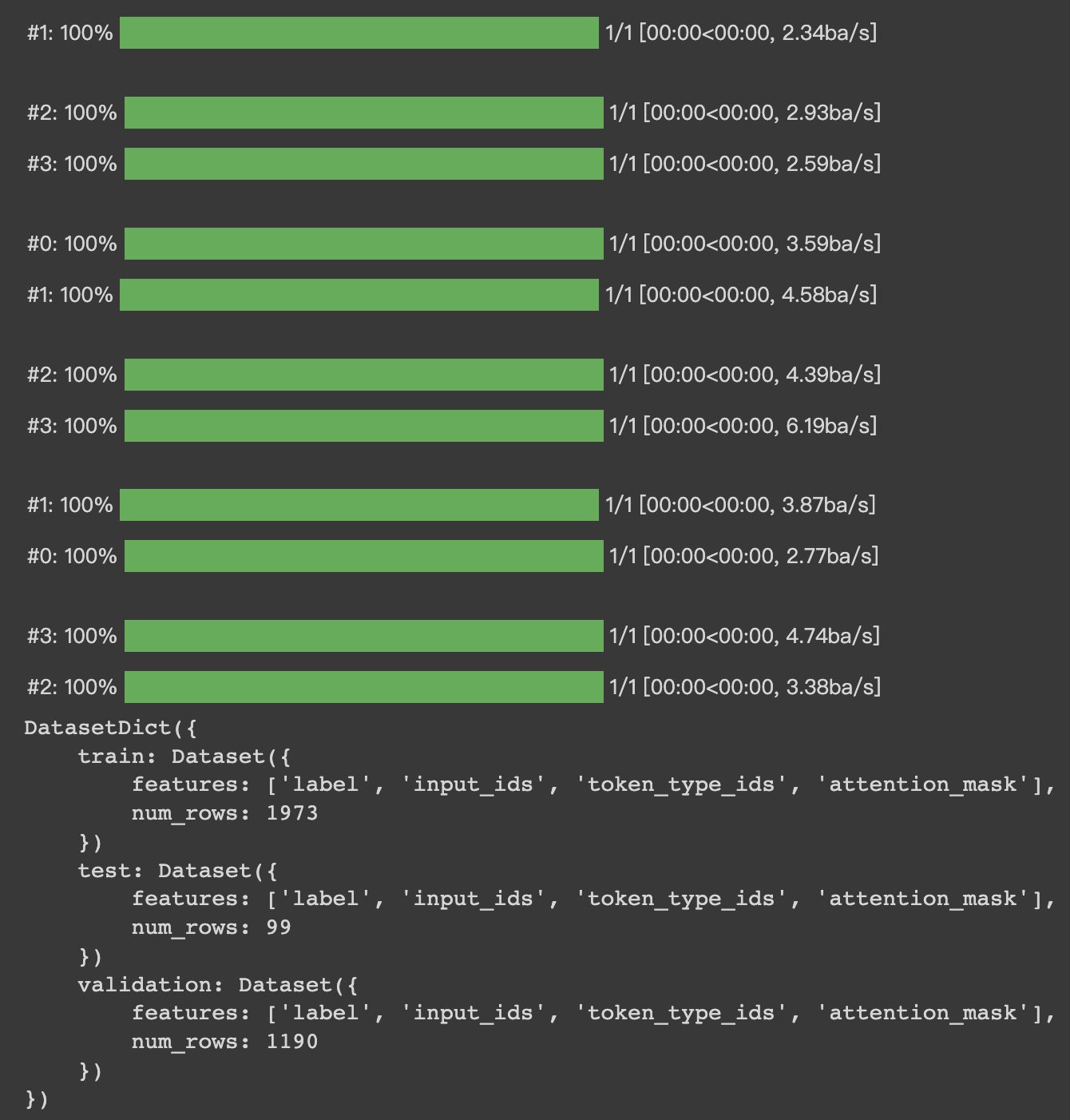 tn2>可以看到数据集中的有部分数据被移除。 ### 定义模型和训练工具 #### 加载预训练模型 tn2>数据集准备好了,现在就可以加载要再训练的模型了,代码如下: ```python from transformers import AutoModelForSequenceClassification model = AutoModelForSequenceClassification.from_pretrained('hfl/rbt3', num_labels=2) #统计模型参数量 sum([i.nelement() for i in model.parameters()]) / 10000 ``` tn2>`hfl/rb3`是一个基于中文文本数据训练的BERT的模型,在代码的最后一行记录该模型的参数,大概3800万个。  tn2>加载了模型之后,对模型进行试算一下: ```python import torch #模拟一批数据 data = { 'input_ids': torch.ones(4, 10, dtype=torch.long), 'token_type_ids': torch.ones(4, 10, dtype=torch.long), 'attention_mask': torch.ones(4, 10, dtype=torch.long), 'labels': torch.ones(4, dtype=torch.long) } #模型试算 out = model(**data) out['loss'], out['logits'].shape ```  tn2>模型的输出包括两部分,一部分是loss,另外一部分是logits。(这里就是模拟没仍和意义) #### 定义评价函数 tn2>为了便于在训练过程中观察模型的性能,需要定义一个评价指标函数。 这里我们缇娜家正确率的指标函数: ```python from datasets import load_metric metric = load_metric('accuracy') ``` tn2>由于模型计算的输出和评价指标要求的还是有差别,所以需要定义一个转换函数,把模型计算的输出转换成评价指标可以计算的数据类型,这个函数就是在训练过程中真正要用到的评价函数,代码如下: ```python import numpy as np from transformers.trainer_utils import EvalPrediction def compute_metrics(eval_pred): logits, labels = eval_pred # 最大值的索引 logits = logits.argmax(axis=1) return {'accuracy': (logits == labels).sum() / len(labels)} #return metric.compute(predictions=logits, references=labels) #模拟输出 eval_pred = EvalPrediction( predictions=np.array([[0, 1], [2, 3], [4, 5], [6, 7]]), label_ids=np.array([1, 1, 0, 1]), ) compute_metrics(eval_pred) ``` tn2>这段代码中,不仅定义了评价函数,还对该函数进行了试算,运行结果如下:  #### 定义训练超参数 tn2>在开始训练之前,需要定义好超参数,HuggingFace使用TrainingArguments对象来封装超参数,代码如下: ```python from transformers import TrainingArguments #定义训练参数 args = TrainingArguments( #定义临时数据保存路径 output_dir='./output_dir', #定义测试执行的策略,可取值no、epoch、steps evaluation_strategy='steps', #定义每隔多少个step执行一次测试 eval_steps=30, #定义模型保存策略,可取值no、epoch、steps save_strategy='steps', #定义每隔多少个step保存一次 save_steps=30, #定义共训练几个轮次 num_train_epochs=1, #定义学习率 learning_rate=1e-4, #加入参数权重衰减,防止过拟合 weight_decay=1e-2, #定义测试和训练时的批次大小 per_device_eval_batch_size=16, per_device_train_batch_size=16, #定义是否要使用gpu训练 no_cuda=False, ) ``` tn2>TrainingArguments对象中可以封装的超参数有很多, 更多请参考:https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments #### 定义训练器 tn2>完成了上面的准备工作,现在可以定义训练器,代码如下: ```python from transformers import Trainer from transformers.data.data_collator import DataCollatorWithPadding #定义训练器 trainer = Trainer( model=model, args=args, train_dataset=dataset['train'], eval_dataset=dataset['test'], compute_metrics=compute_metrics, data_collator=DataCollatorWithPadding(tokenizer), ) ``` tn2>定义训练器时需要传递要训练的模型、超参数对象、训练和验证数据集、评价函数,以及数据整理函数。 #### 数据整理函数 tn2>DataCollatorWithPadding对象能把批次中长短不一的句子补充成统一的长度,模型期待的数据类型也是矩阵,所以经过数据处理之后,数据即被整理成模型可以计算的矩阵格式。例子如下: ```python data_collator = DataCollatorWithPadding(tokenizer) #获取一批数据 data = dataset['train'][:5] #输出这些句子的长度 for i in data['input_ids']: print(len(i)) #调用数据整理函数 data = data_collator(data) #查看整理后的数据 for k, v in data.items(): print(k, v.shape) ``` 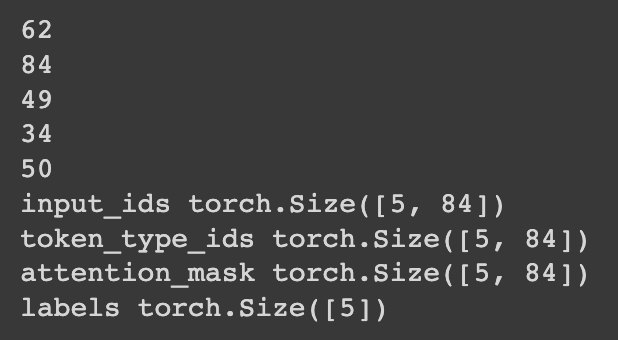 tn2>我们可以通过下面的代码查看句子时怎么被补长的。 ```python tokenizer.decode(data['input_ids'][0]) ``` tn2>可以看到,数据整理函数时通过对句子的尾部补充PAD来对句子补长的。  ### 训练和测试 #### 训练模型 tn2>在开始训练之前,不妨直接对模型进行一次测试,先定下训练前的基准,在训练结束后再对比这里得到的基准,以验证训练的有效性,代码如下: ```python trainer.evaluate() ``` 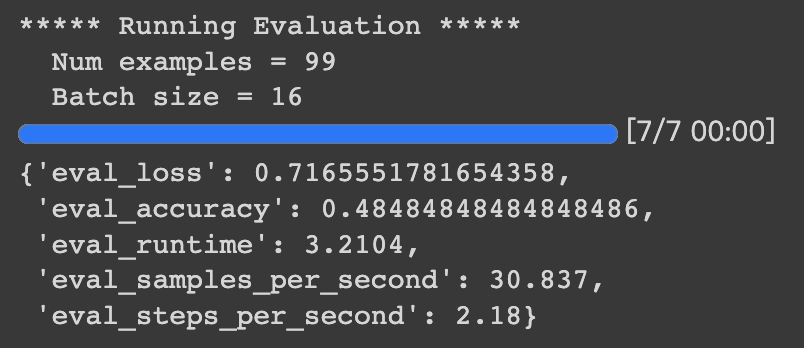 tn2>在模型训练之前只有`48%`的正确率。 接下里我们对模型进行训练: ```python trainer.train() ``` tn2>从该日志中的`Total optimization steps = 124`可知,本次有124个训练,由于定超参数时定了每个steps执行一次测试,并保存模型参数,所以当训练结束时,期待4次测试结果,并有4个保存的参数模型。 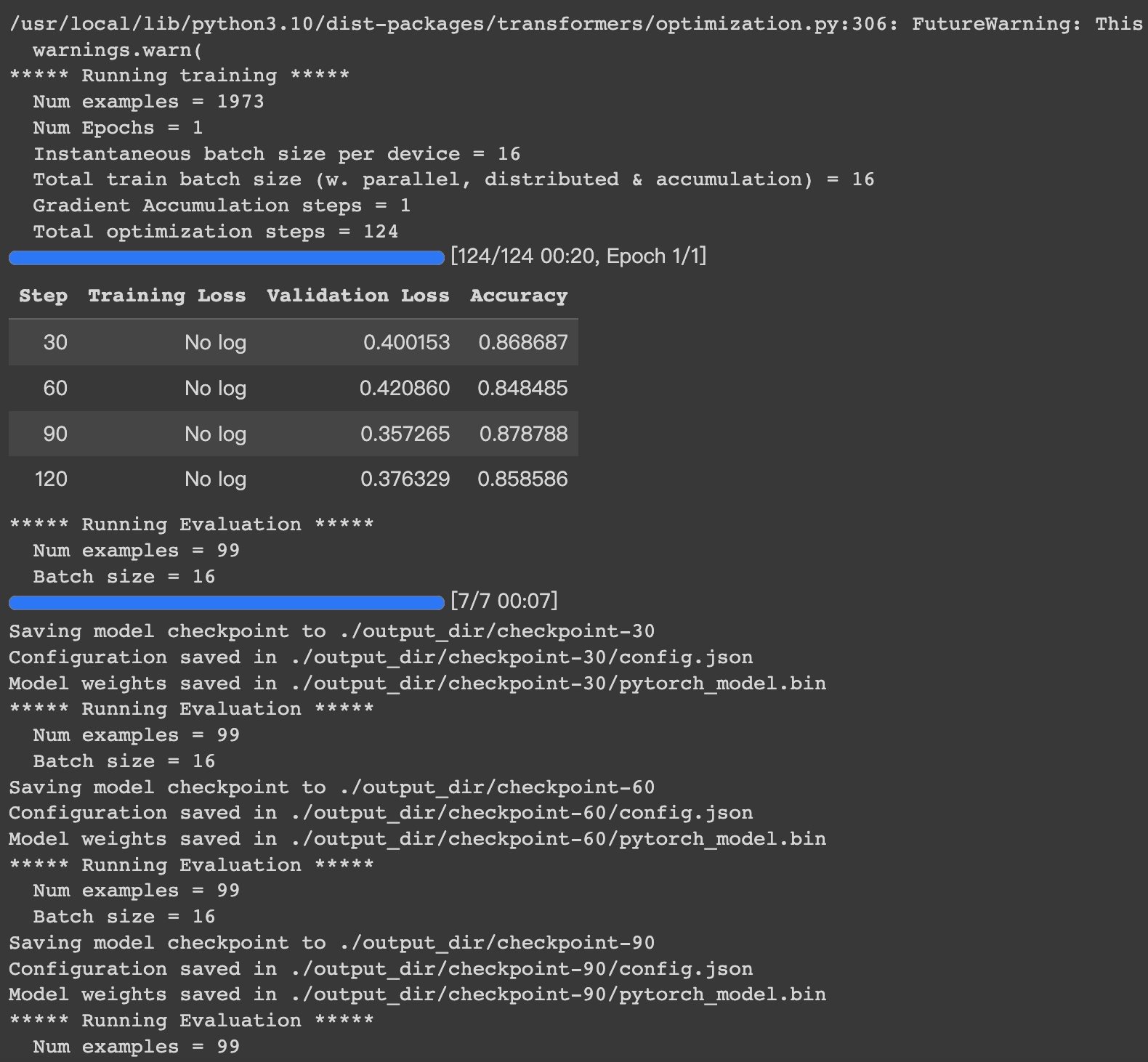 | 列名 | 描述 | | ------------ | ------------ | | `Step` | 表示测试执行的时的`steps` | | `Training Loss` | 表示训练loss,在本次任务中未记录。 | | `Validation Loss` | 表示验证集上测试得出的loss | | `Accuracy` | 表示在验证集上测试得出的正确率,最后得到的正确率为`85%`。 | tn2>这个正确率其实不算太理想,待会我还会通过`v100`开启GPU进行训练测试一下。 我们可以在`output_dir`文件夹中找到4个模型文件夹,这是对应步数保存的检查点。 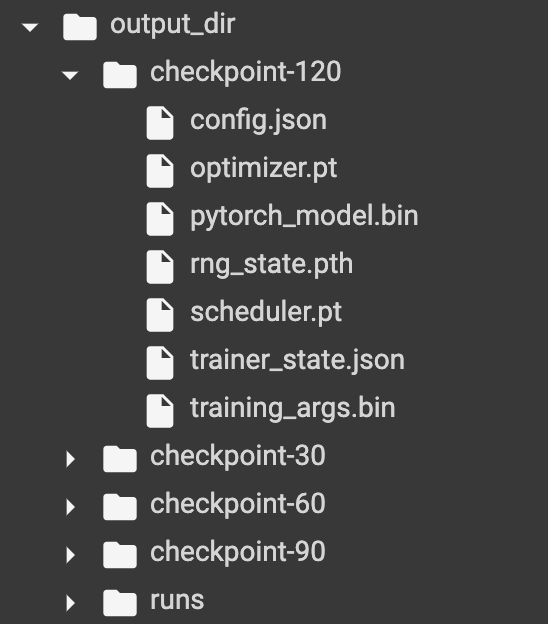 tn2>如果在某个训练过程中由于各种原因导致导致训练中断,或者希望从某个检查点重新训练模型,则可以使用训练器的`train()`函数的`resume_from_checkpoint`参数设定检查点,从该检查点重新训练,代码如下: ```python trainer.train(resume_from_checkpoint='./output_dir/checkpoint-90') ``` tn2>它会跳过前面的90个训练后面的34个,会覆盖掉`checkpoint-120`文件夹。  tn2>在训练结束后,不妨再执行一次测试,以测试模型的性能,代码如下: ```python trainer.evaluate() ``` tn2>可以看到模型最终的性能正确率为`86%`。 #### 模型的保存和加载 tn2>训练得到满意的模型后,可以动手将该模型的参数保存到磁盘上,以备以后需要时加载,代码如下: ```python #手动保存模型参数 trainer.save_model(output_dir='./output_dir/save_model') ``` tn2>加载模型参数的方法如下: ```python #手动加载模型参数 import torch model.load_state_dict(torch.load('./output_dir/save_model/pytorch_model.bin')) ``` #### 使用模型预测 tn2>最后介绍使用模型进行预测的方法,代码如下: ```python # 将模型设置为评估模式 model.eval() # 这个循环通过评估数据加载器获取一个数据批次,然后立即退出循环。 for i, data in enumerate(trainer.get_eval_dataloader()): break # 这段代码将示例数据批次中的所有张量数据移动到 CUDA 设备(通常是 GPU),以便在 GPU 上进行推断。 for k, v in data.items(): data[k] = v.to('cuda') # 数据批次传递给模型以获取模型的输出。 out = model(**data) # 计算模型输出中每个样本的预测标签。 out = out['logits'].argmax(dim=1) # 将输入的标记(tokens)转换回文本。然后,打印真实标签和模型的预测标签。 for i in range(16): print(tokenizer.decode(data['input_ids'][i], skip_special_tokens=True)) print('label=', data['labels'][i].item()) print('predict=', out[i].item()) ``` tn2>在这段代码中,首先把模型切换到运行模式,然后从测试数据集中获取一个批次的数据用于预测,之后把这批数据输入模型进行计算,得出的结果即为模型预测的结果,最后输出前4句的结果,并与真实的label进行比较,运行结果如下:  ## 其他 ### 使用V100跑 tn2>超参数该的GPU选项钩上。 ```python no_cuda=False ```  tn2>训练前,只有49%的正确率:  tn2>训练后,只花了12秒就训练完了,但正确率很低还是`87%`,我们通过更改轮次多训练几次: 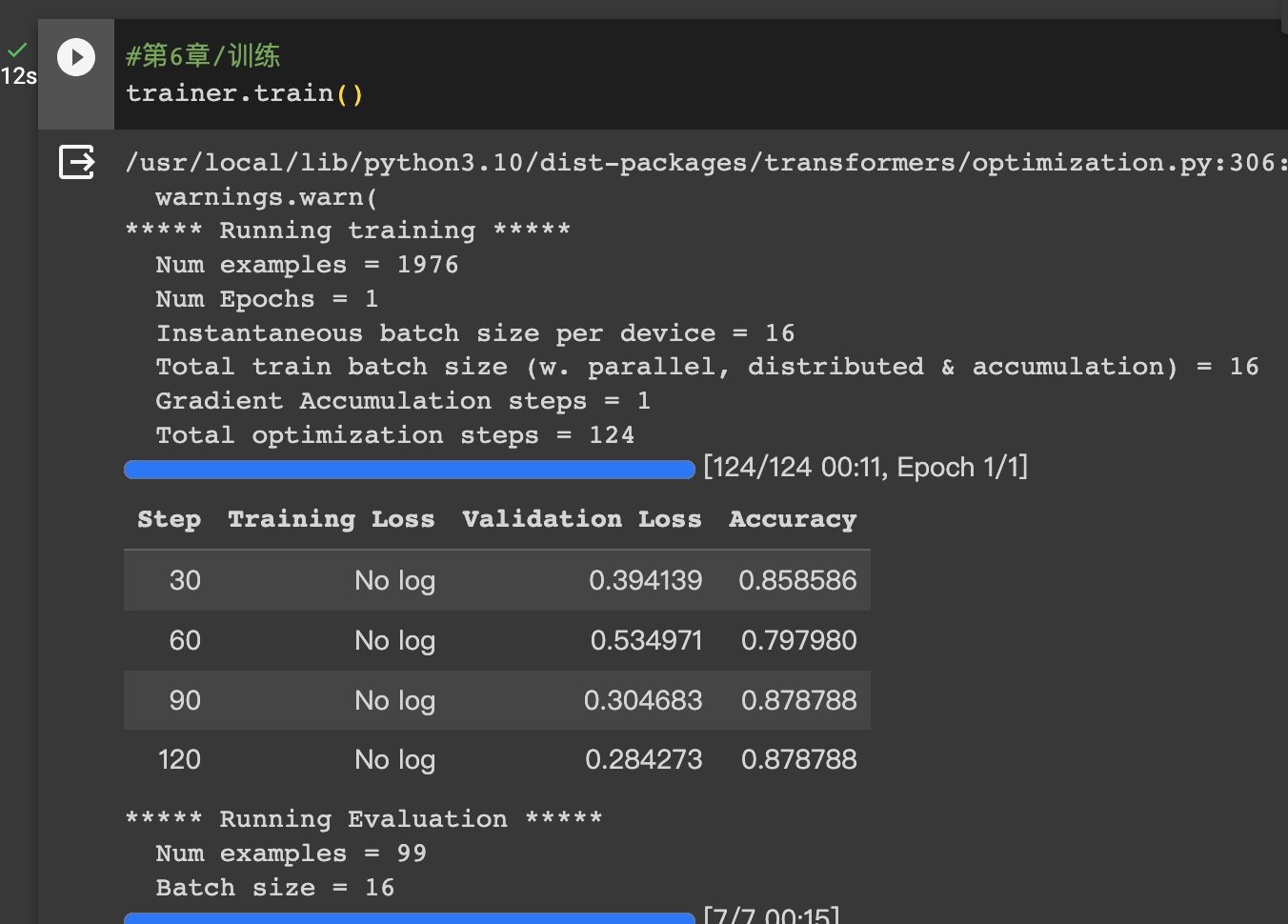 tn2>改了一下配置重新训练了一下这次感觉要乐观很多,`92%`。 ```python from transformers import TrainingArguments #定义训练参数 args = TrainingArguments( #定义临时数据保存路径 output_dir='./outputxxxp_dir', #定义测试执行的策略,可取值no、epoch、steps evaluation_strategy='steps', #定义每隔多少个step执行一次测试 eval_steps=30, #定义模型保存策略,可取值no、epoch、steps save_strategy='steps', #定义每隔多少个step保存一次 save_steps=30, #定义共训练几个轮次 num_train_epochs=20, #定义学习率 learning_rate=3e-4, #加入参数权重衰减,防止过拟合 weight_decay=1e-3, #定义测试和训练时的批次大小 per_device_eval_batch_size=32, per_device_train_batch_size=32, #定义是否要使用gpu训练 no_cuda=False, ) ``` 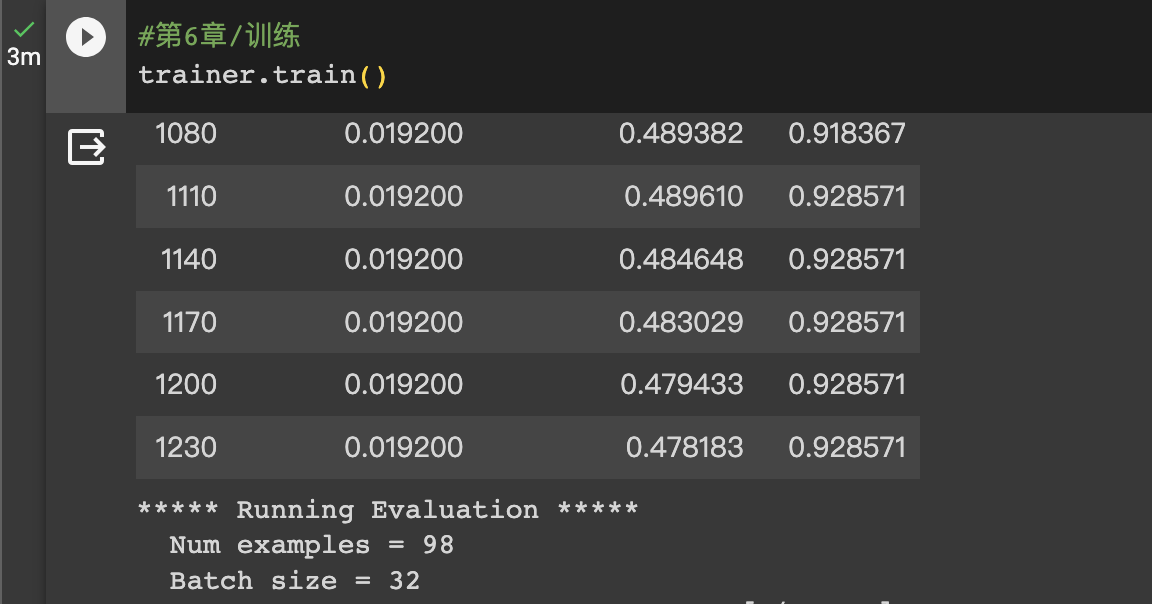 tn2>但是请看我跑之前的和跑之后的GPU用量。。。。  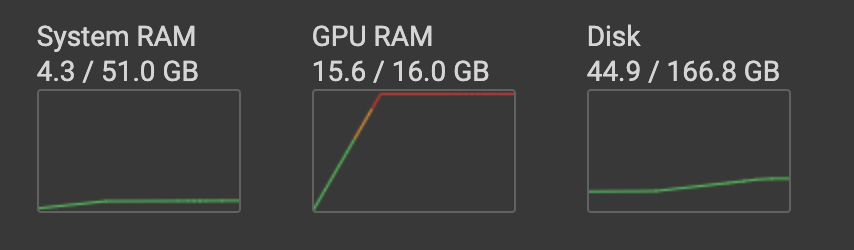
欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739
👈{{preArticle.title}}
👉{{nextArticle.title}}
评价
{{titleitem}}
{{titleitem}}
{{item.content}}
{{titleitem}}
{{titleitem}}
{{item.content}}
尘叶心繁
这一世以无限游戏为使命!
博主信息
排名
6
文章
6
粉丝
16
评论
8
文章类别
.net后台框架
176篇
linux
17篇
linux中cve
1篇
windows中cve
0篇
资源分享
10篇
Win32
3篇
前端
28篇
传说中的c
5篇
Xamarin
9篇
docker
15篇
容器编排
101篇
grpc
4篇
Go
15篇
yaml模板
1篇
理论
2篇
更多
Sqlserver
4篇
云产品
39篇
git
3篇
Unity
1篇
考证
2篇
RabbitMq
23篇
Harbor
1篇
Ansible
8篇
Jenkins
17篇
Vue
1篇
Ids4
18篇
istio
1篇
架构
2篇
网络
7篇
windbg
4篇
AI
18篇
threejs
2篇
人物
1篇
嵌入式
16篇
python
18篇
HuggingFace
8篇
pytorch
10篇
opencv
6篇
Halcon
5篇
最新文章
最新评价
{{item.articleTitle}}
{{item.blogName}}
:
{{item.content}}
关于我们
ICP备案 :
渝ICP备18016597号-1
网站信息:
2018-2024
TNBLOG.NET
技术交流:
群号656732739
联系我们:
contact@tnblog.net
欢迎加群
欢迎加群交流技术


 分类:
HuggingFace
分类:
HuggingFace
分类:
HuggingFace
分类:
HuggingFace


