

 分类:
.net后台框架
分类:
.net后台框架
HtmlAgilityPack 网络数据处理
新年新气象!祝大家新的一年里蓬勃发展,飞黄腾达,幸福健康!
今天讲的是一款处理网络数据的框架HtmlAgilityPack ,
相信许多同行都因为处理网页数据写正则表达式而搞得焦头烂额,如果你使用这款框架会让你如鱼得水,释放你沉淀已久的复杂心情!
简介:
这是一个敏捷的HTML解析器,它构建了一个读/写DOM,并支持普通的xpath或xslt(您实际上不需要理解xpath或xslt就可以使用它,不用担心…)。
它是一个.NET代码库,允许您解析“离开Web”的HTML文件。
解析器对“真实世界”格式错误的HTML非常宽容。对象模型与System.xml的建议非常相似,但对于HTML文档(或流)。
原理:把抓取下来的网页转为Dom文档模型(xml),然后进行元素查找
动手小案例:
(1)首先创建一个 控制台 项目 learningHtmlAgilityPack

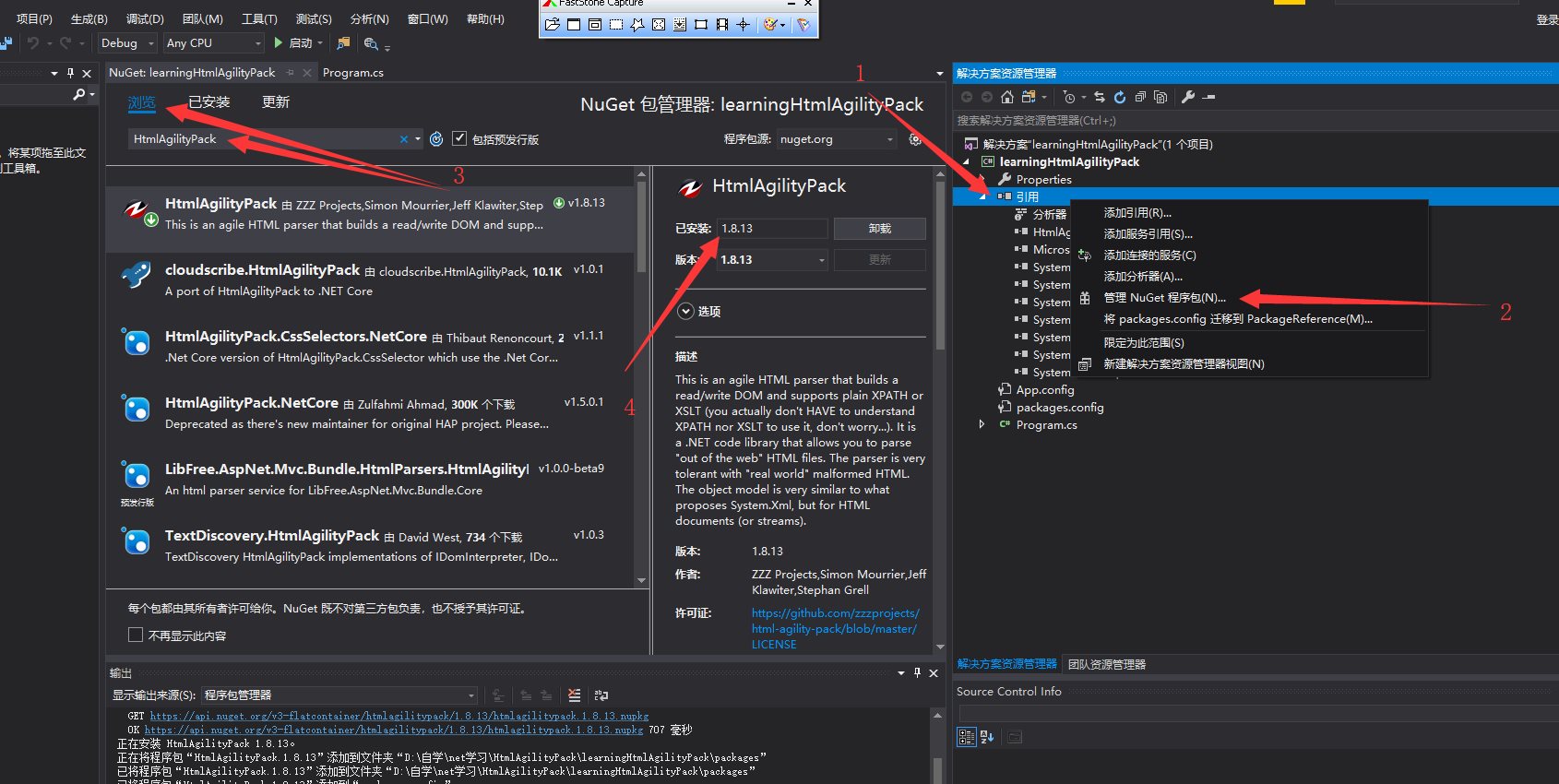
(2)选中引用右键-->点击 管理NuGet程序包-->点击浏览-->搜索HtmlAgilityPack
由此我们看到我们这里的最新稳定版为 v1.8.13 然后点击 安装 就可以了
(3)安装完成之后,我们将以百度为案例,从中获取一下 百度搜索 按钮的值
1,打开开发者工具获取百度搜索按钮的XPath路径 ,确认无误后进行下一步操作 (注意:Chome浏览器可以识别类,id等元素属性;火狐将会从/head开始找起走)
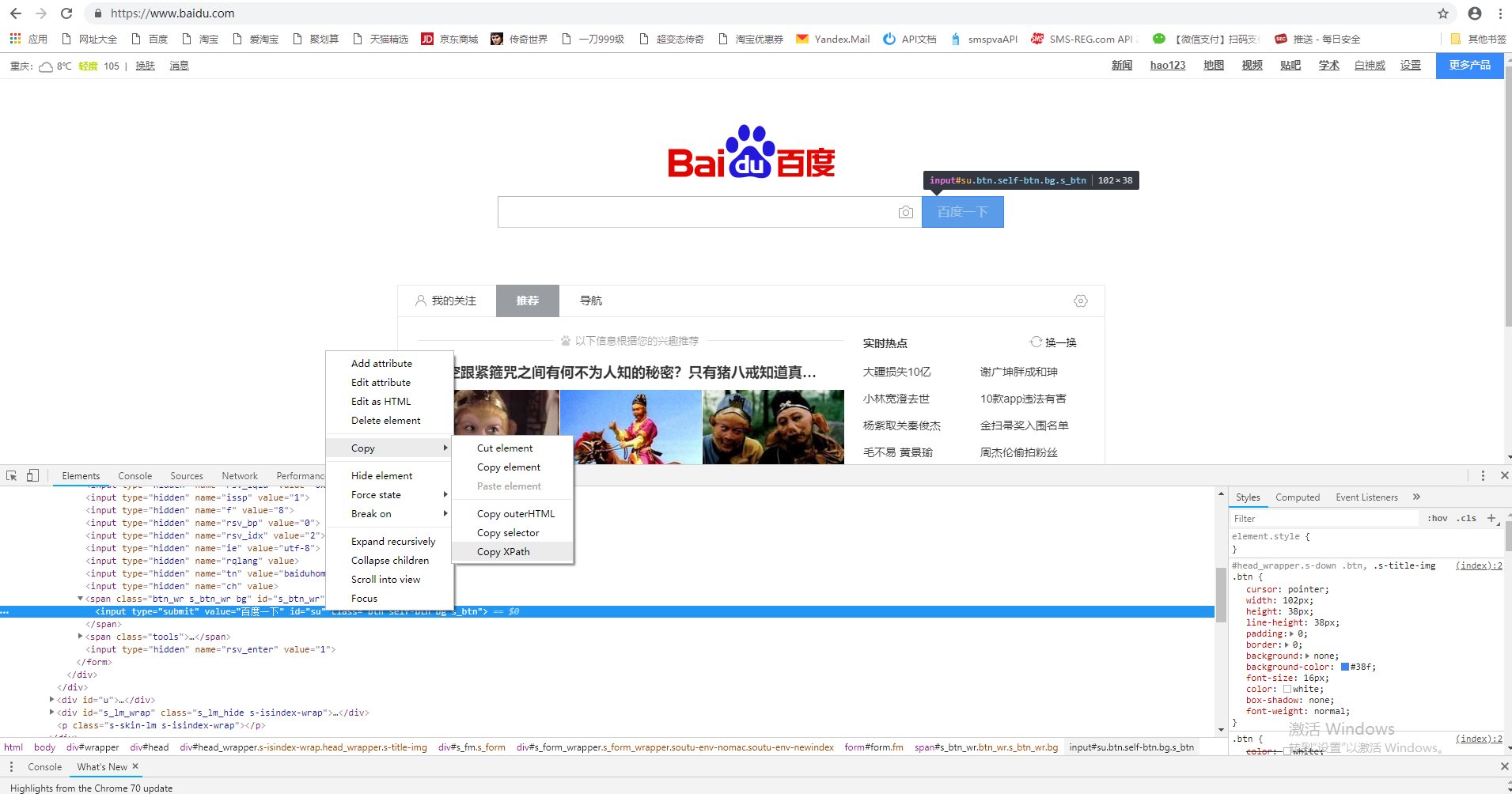
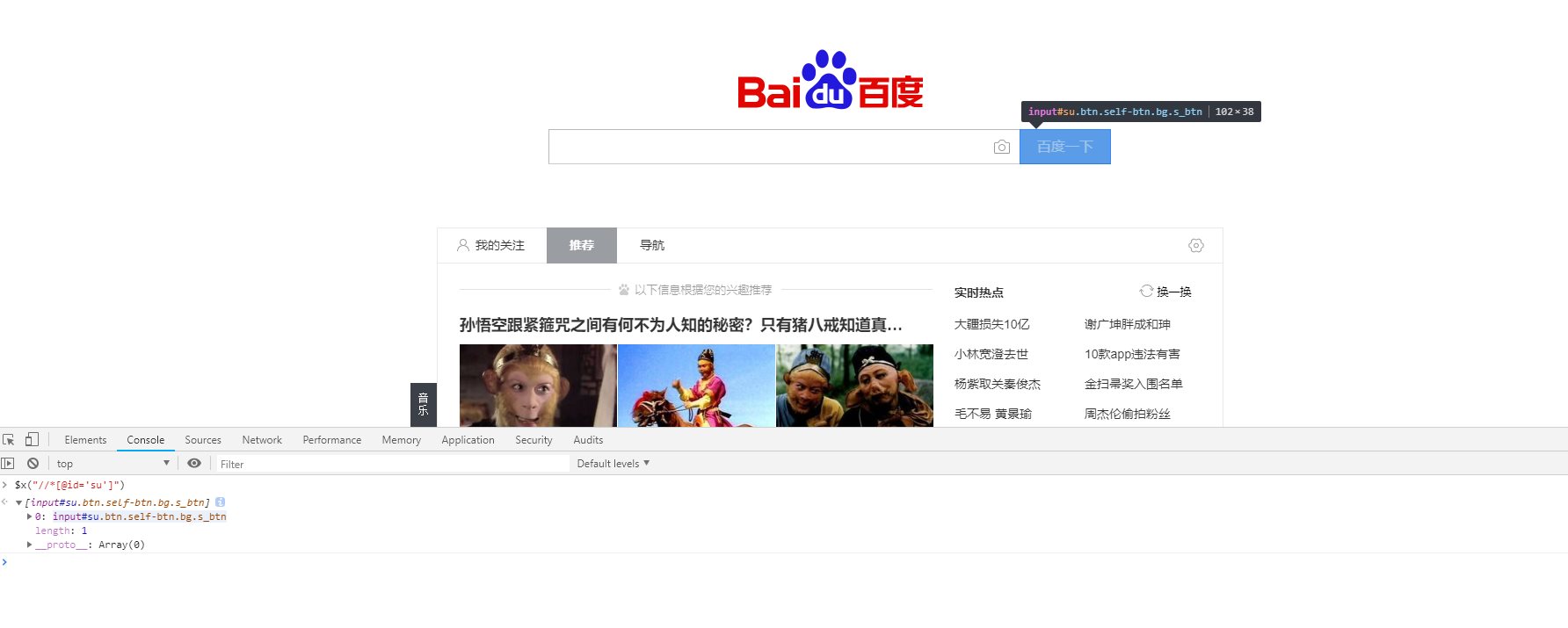
2,通过简洁的代码达成目的
using System.Net;
namespace learningHtmlAgilityPack
{
class Program
{
static void Main(string[] args)
{
//实例化常规请求方式
WebClient wc = new WebClient();
//获取网页数据
var vb = wc.DownloadData("https://www.baidu.com/");
//转码
var str = System.Text.Encoding.UTF8.GetString(vb);
//实例化 HtmlAgilityPack 对象模型
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载文档对象模型
doc.LoadHtml(str);
//获取到百度按钮节点 把我们刚刚复制的XPath粘贴上去
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("//*[@id='su']");
//获取值 1,元素名称 2,当没有该元素时返回的内容
string value = htmlnode.GetAttributeValue("value", "");
System.Console.WriteLine(value);
System.Console.ReadKey();
}
}
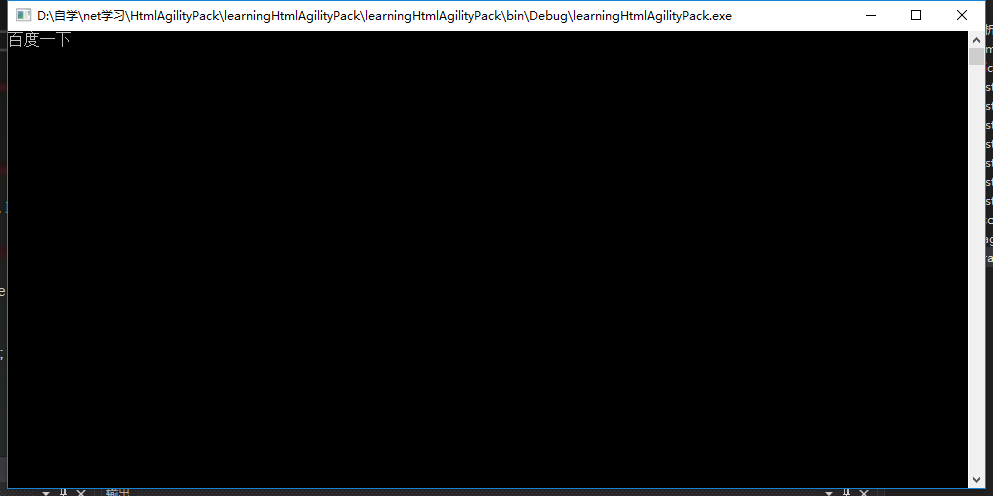
}运行结果:
疑难杂症:
(1),实现获取多个标签的集合(通过遍历获取到其中的每一个元素)
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//想怎么干就怎么搞xxxxx
}
}(2),如果在item下面还有更多的便签或一个标签时照样这样写,只不过在获取第二层的时候XPath不需要//
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//HtmlAgilityPack.HtmlNode htmlnode = item.SelectSingleNode("//*[@id='su']");
HtmlAgilityPack.HtmlNodeCollection childs = item.SelectSingleNode("ul/li");
foreach(var singeitem in childs)
{
//xxxx
}
}
}欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739


 50010702506256
50010702506256
