


排名
6
文章
6
粉丝
16
评论
8
{{item.articleTitle}}
{{item.blogName}} : {{item.content}}
ICP备案 :渝ICP备18016597号-1
网站信息:2018-2026TNBLOG.NET
技术交流:群号656732739
联系我们:contact@tnblog.net
公网安备: 50010702506256
50010702506256
50010702506256

欢迎加群交流技术

 分类:
Python
分类:
Python
有时候数据出了问题,可以从日志中恢复数据(如果你没记日志..没备份..→_→..)
一、日志展示
介绍个平常自己用的小方法,如果你的日志没有单独的模块或页面管理的话
日志记录在文件中,可以在IIS中新建一个站点 指向你的日志文件,站点开启目录浏览
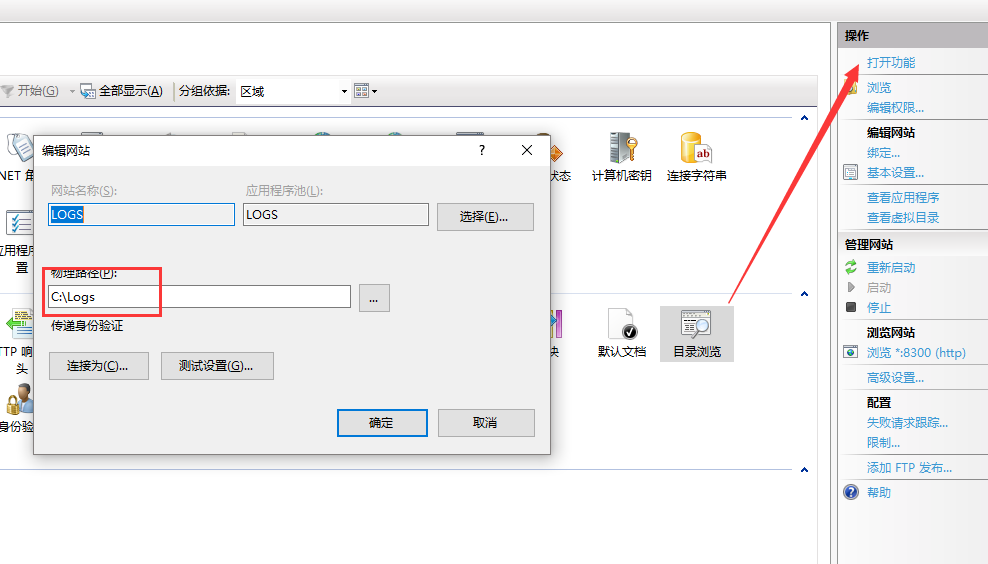
然后就可以
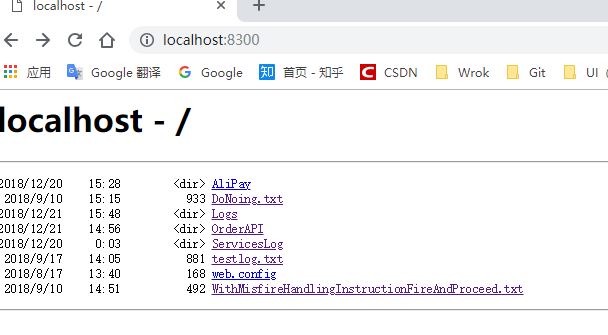
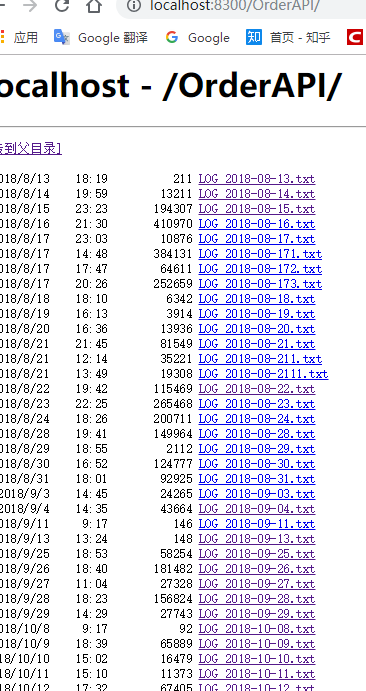
就可以比较方便看 查找之类..
二、抓取数据
然后就是抓取的问题了,用python把网页源码抓取下来,根据需求拿数据 当然如果你能直接拿到日志文件 用IO读取文件的方式(你本地的情况下,一般生产环境的日志你应该访问不到)更容易
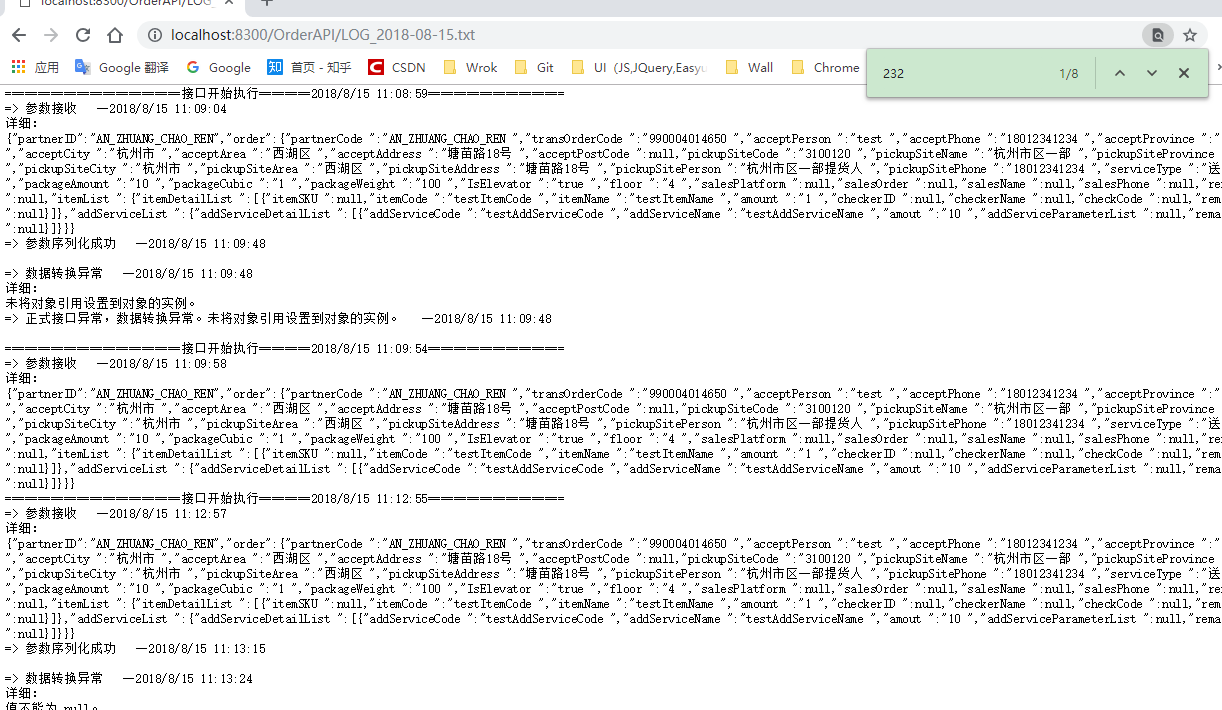
我要取日志中到货更新的时间:

代码:
import json
import urllib.request
import re
import threading
import pymysql
def GetContent(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req).read()
return data
conn = pymysql.connect('数据库IP地址', 'name', 'password', 'DB_NAME')
excuter = conn.cursor()
#太多可以使用多线程抓取
for i in range(18):
i+=1
if(i<10):
url='http://localhost:8300/OrderAPI/LOG_2018-12-0'+str(i)+'.txt'
else:
url='http://localhost:8300/OrderAPI/LOG_2018-12-'+str(i)+'.txt'
data = GetContent(url).decode('utf-8')
content = re.findall(re.compile('到货状态更新成功。 一(.*?)\r\n详细:\r\nid:(.*?)。OrderCode:(.*?)\r\n',re.S), data)#.*? "到货状态更新成功。 一(.*?)\r
for item in content:
sql = "update t_order set Time1='"+str(item[0])+"' where Id="+str(item[1])
print(sql)
excuter.execute(sql)
conn.commit()
print('Tosql Succ!!!')
excuter.close()
conn.close()需要注意 需要下载一个连接操作mysql的库 :pip install PyMySQL
结果: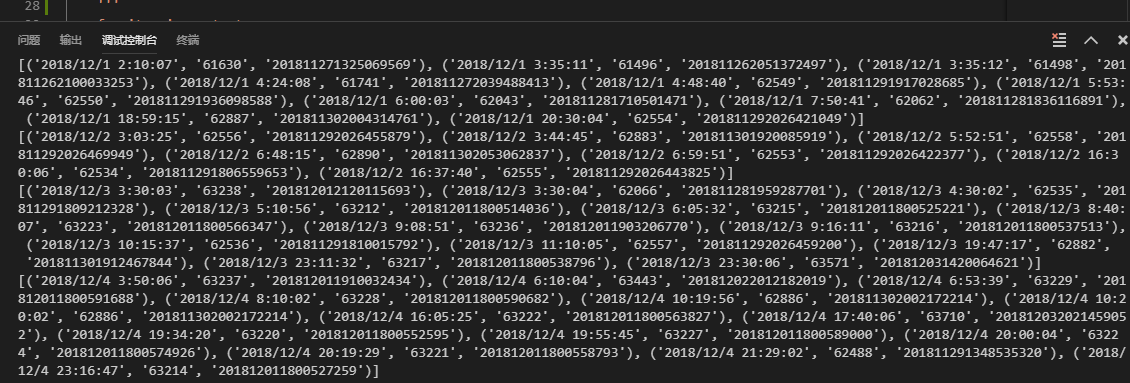
数据拿回来了,想怎么操作都行,数据太多可以用多线程来抓取
python的代码贴过来就乱了 有点难受
具体情况 根据你的需要来,怎么抓取怎么操作,这篇文章只是提供一个思路
欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739
评价